Pandas
데이터 저장, 호출
- seaborn 라이브러리에 존재하는 데이터 불러와 csv파일로 저장
- index 파라미터는 데이터의 인덱스 저장 여부를 결정

- 또는 데이터 호출 시 인덱스 부분을 제거하고 가져오는 방식도 있음

- 엑셀 파일의 경우는 pd.to_excel 사용
- 인덱스 미지정

- 인덱스 지정

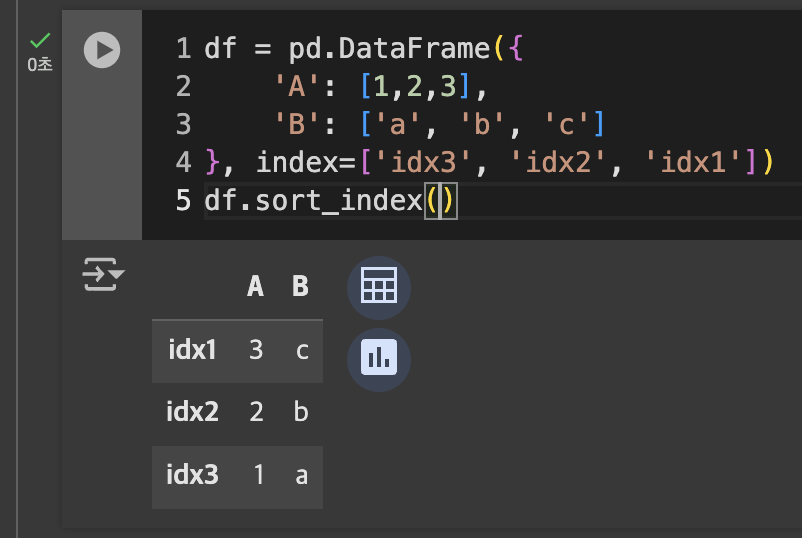
- 인덱스 정렬 함수: sort_index()
- 컬럼을 인덱스로 사용: set_index()

- 인덱스의 정보와 타입을 확인: index
- 인덱스 변경: index

- 인덱스를 기존 값으로 설정: rest_index()
- 기존 인덱스 열 누락 여부 결정위한 drop 파라미터

컬럼
데이터 프레임 생성

- 컬럼 호출(시리즈 형태)

컬럼명 정보: columns

- 컬럼명 변경

- 특정 컬럼명만 변경: rename

- 컬럼 추가

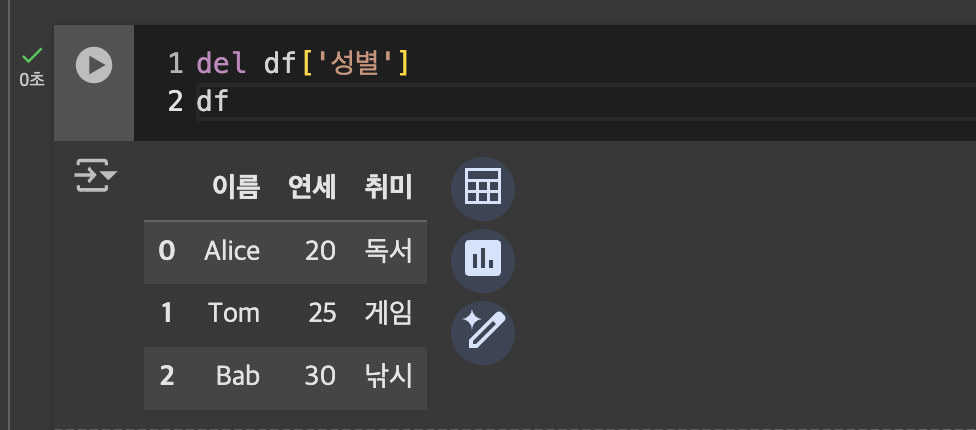
- 컬럼 제거: del
데이터 확인
df.head() ➡️ 데이터의 첫 행부터 몇 개만 가져옴
df.tail() ➡️ 데이터의 마지막 행부터 몇 개만 가져옴
df.info() ➡️ 데이터에 대한 정보(컬럼명, 결측치의 수, 데이터 타입)를 알 수 있음
df.describe() ➡️ count, mean, std, min, max, 4분위 값을 알 수 이음

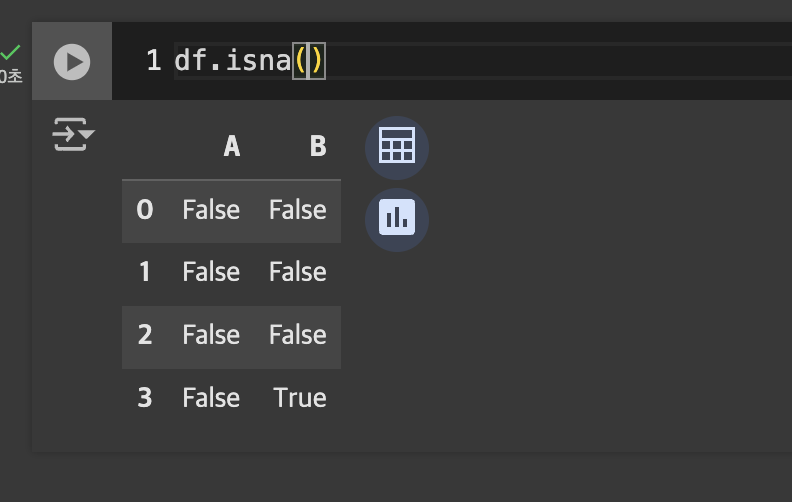
- 구체적인 널값을 확인: df.isna()
- 컬럼을 지정해서 확인

데이터 타입
- df.info() 방법도 있지만 df.dtypes도 가능하다
- 한 개의 컬럼만 보기 위해서는 df['tip'].dtype 사용

- 데이터 타입을 변경

데이터 선택
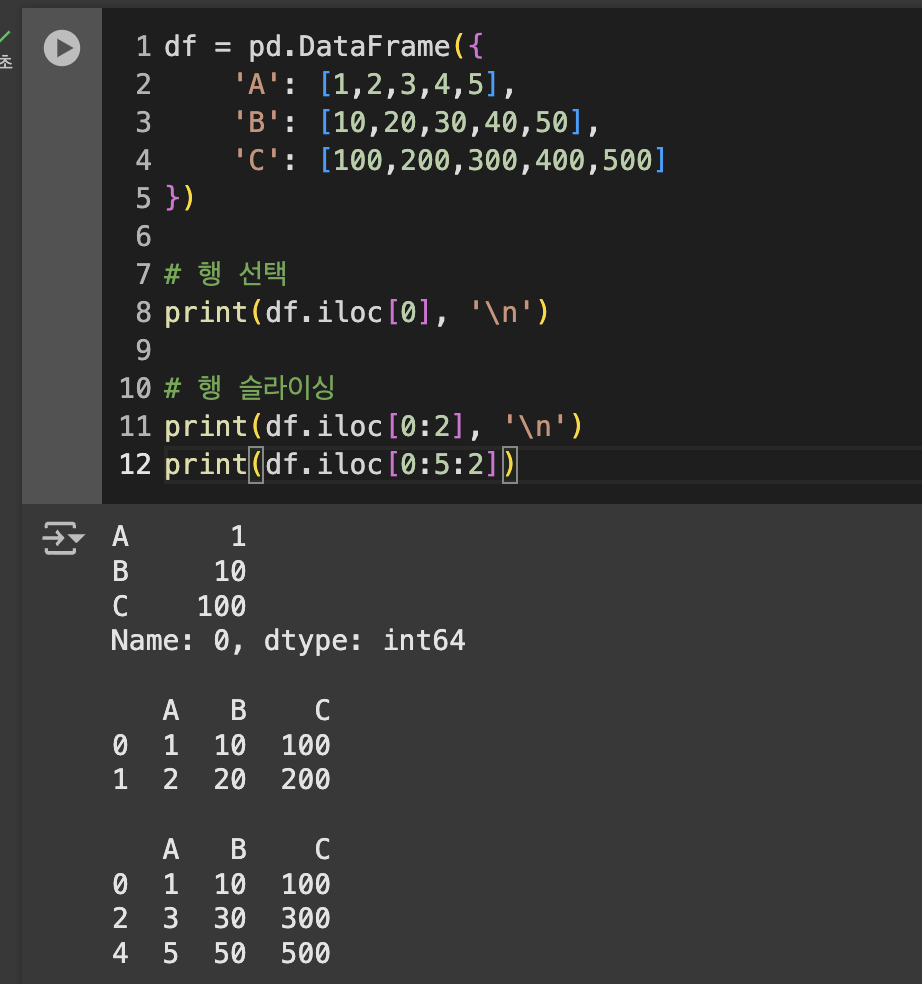
.iloc ➡️ 컬럼에 대한 번호로 호출

.loc ➡️ 인덱스와 컬럼명으로 슬라이싱
- loc를 사용하기 위해서는 인덱스가 있어야 함

데이터 슬라이싱

- 순서 변경도 가능

불리언 인덱싱
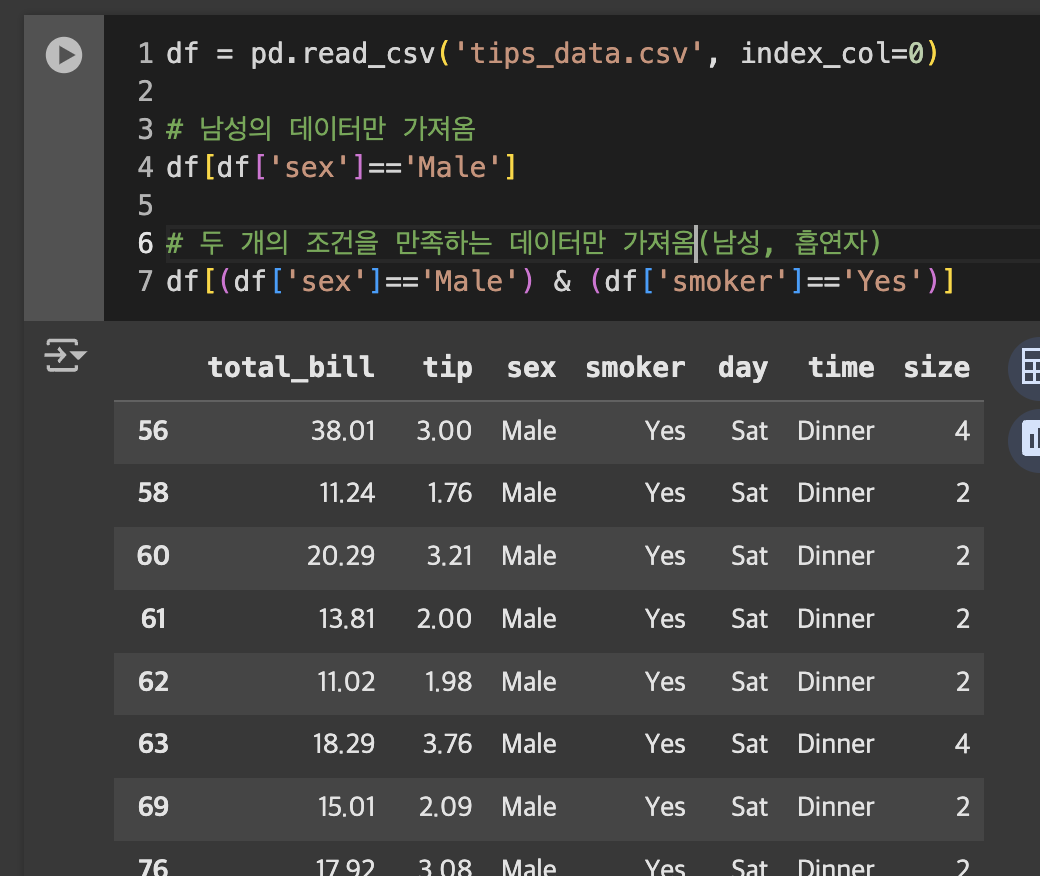

값에 해당하는 데이터만 가져옴 ➡️ isin()

- 변수에 담아 사용 가능

데이터 추가하기

- object 타입의 날짜 데이터를 datetime 타입으로 변경

- 실수 타입 두 개의 컬럼을 합쳐 새로운 컬럼 생성

데이터 병합
두 데이터 프레임을 합치는 것 ➡️ concat
- 데이터가 없는 경우에는 null 값으로 채워짐

- 위 아래로 병합

- 옆으로 병합

특정 컬럼을 고려해 결합 ➡️ merge
- on은 어떤 컬럼을 기준으로 할지 결정

- 병합하는 방식이 여러가지가 있음 how='inner'가 기본값
- 겹치는 값들을 가져옴

- how='outer'
- 다 가져옴

- how='left'
- 왼쪽이 기준

- how='right'
- 오른쪽이 기준

데이터 집계
groupby ➡️ 특정 기준에 따라 그룹 나누고 이를 기반으로 집계, 변환, 필터링 등 가능


실습

- agg 이용해 각 원하는 것을 지정

Pivot table

- 값이 없으면 null로 출력

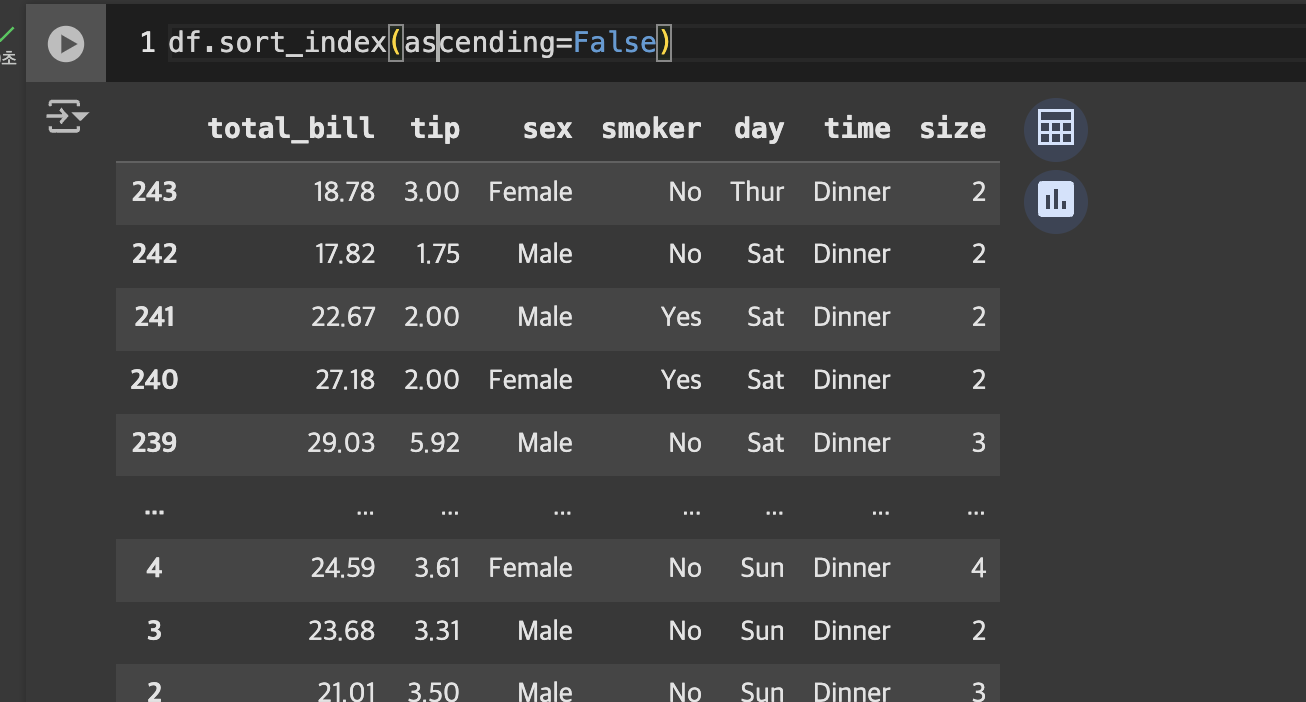
정렬
- 팁 변수를 기준으로 정렬
- 기본 값은 오름차순
- 내림차순으로 정렬하려면 ascending=False 추가

- total_bill 기준으로 오름차순 정렬 후 tip 기준으로 내림차순 정렬

- 인덱스도 내림차순 정렬이 가능
'EDA & 데이터 분석 > 데이터분석' 카테고리의 다른 글
| 엔진 센서 데이터 기반 결함 예측 및 품질관리 분석(1) (0) | 2025.02.24 |
|---|---|
| 데이터 전처리 & 시각화 4주차(시각화) (0) | 2025.01.03 |
| 데이터 전처리 & 시각화 2주차 (0) | 2024.12.31 |
| 데이터 전처리 & 시각화 1주차 (0) | 2024.12.31 |
| 데이터 리터러시 (4) | 2024.12.30 |