EDA & 데이터 분석/데이터분석
엔진 센서 데이터 기반 결함 예측 및 품질관리 분석(1)
edcrfv458
2025. 2. 24. 15:49
엔진 센서 데이터 기반으로 정상(0)/불량(유형 1, 2, 3) 분류
변수
- MAP: 흡기 매니폴드 절대압, 대략 0~5 kPa
- TPS: 스로틀 개도율
- Force: 엔진에서 측정된 힘, 대략 0~400 N
- Power: 엔진에서 발휘되는 출력, 0~35 kW
- RPM: 엔진 회전수, 대략 1000~4000 RPM
- Consumption L/H: 시간단 연료 소묘율, 0~10 I/h
- Consumption L/100km: 주행거리당 연료 소비랑
- Speed: 차량 속도
- CO: 배기가스 중 일산화탄소 비율
- HC: 배기가스 중 탄화수소 농도
- CO2: 배기가스 중 이산화탄소 비율
- O2: 배기가스 중 산소 비율
- Lambda: 공기-연료비 이론치에 대한 실제값의 비율
- AFR: 실제 공기-연료비
- Fault: 엔진 결함 상태
기본 정보 확인



결함 유형(1, 2, 3)과 정상 데이터 분류 예측(1)
결함 유형 1, 2, 3을 1로 만들고 정상 0과 각 변수 분포 확인
- 확실히 정상/불량일 때 변수 간의 차이가 보임

XGBoost 모델





검정


- 정상과 불량은 잘 분류해 냄
- 그렇다면 불량의 유형도 잘 분류할까
결함 유형(1, 2, 3)과 정상 데이터 분류 예측(2)
결함의 갹 유형과 정상 데이터 분포 확인
- 여러 변수에서 차이가 보이긴 하지만 4개가 겹쳐있어 확인이 어려움




- RPM과 Speed, Lambda와 AFR의 상관 계수가 1이고, 다른 변수들 간의 상관 계수를 보았을 때 다중 공선성 문제가 발생할 가능성이 있는 것으로 보인다.
Random Forest 모델





XGBoost 모델



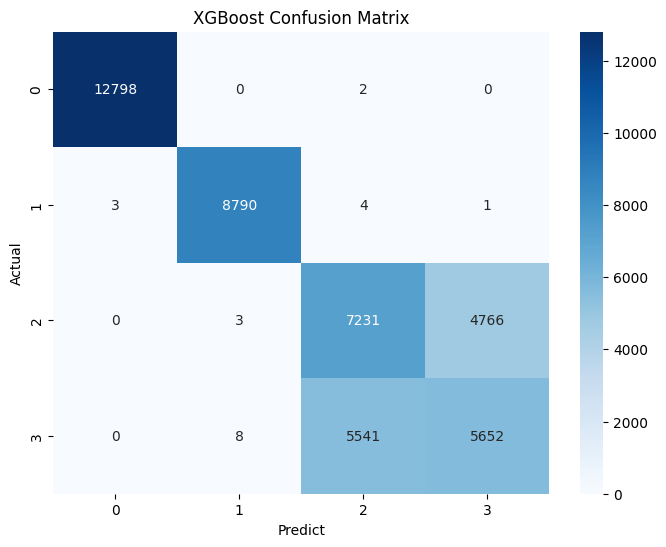

검정


- 랜덤 포레스트와 XGBoost 같은 트리 기반 모델은 변수 간의 독립성을 가정하지 않으며, 다중 공선성이 존재해도 트리가 분할할 변수를 자동으로 선택하기 때문에 영향이 적음
- 하지만 비선형 모델에서도 다중 공선성이 문제가 될 수 있는 경우가 존재
- 불필요한 변수가 많아져 과적합 발생 가능성
- 모델 해석이 왜곡될 가능성
- 학습 데이터 효율성 저하
- 불량 2유형과 3유형을 잘 구별하지 못함
불량 2유형과 3유형을 확인

