AI/머신러닝
머신러닝의 이해와 라이브러리 활용 기초 - 2(로지스틱회귀, 다중로지스틱회귀, 평가)
edcrfv458
2025. 1. 22. 19:52
머신러닝(예측하는 법)
- 숫자를 예측(회귀) ➡️ 선형회귀
- 범주를 예측(분류) ➡️ 로지스틱회귀
타이나틱 생존 분류 문제
타이나틱 탑승객과 사망에 대한 데이터로 0, 1을 맞추는 실습
- 가설을 설정(비상상황 특성상 여성을 배려해 많이 생존했을 것)
- pivot table을 만들어 확인
- 그래프를 통해 확인
import pandas as pd
# 피벗 테이블 생성
pd.pivot_table(titanic_df, index='sex', columns='survived', aggfunc='size')
# aggfunc는 다양한 집계를 적용 가능 sum, max 등 (size는 관측치 개수)
import seaborn as sns
sns.countplot(titanic_df, x='sex', hue='survived')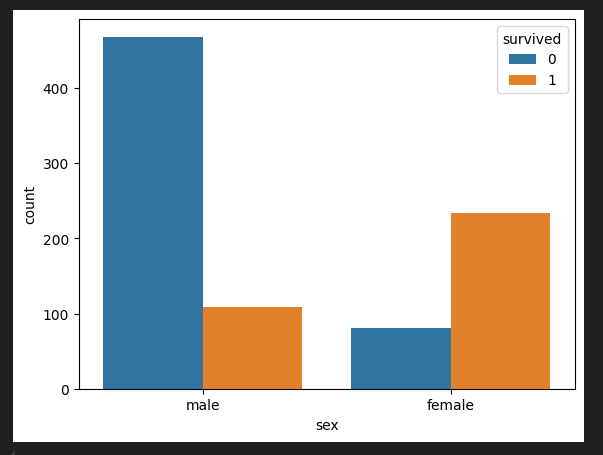
- 정확도(Accuracy): 맞춘 개수 / 전체 데이터
- 생존을 맞춤 ➡️ (233 + 468) / 891 * 100
로지스틱 회귀 이론
범주형 Y에서 선형함수의 관계
- X가 연속형 변수이고, Y가 특정 값이 될 확률이라고 설정
- 확률은 0과 1사이이므로 예측 값이 확률 범위를 넘어 갈 수 있는 문제가 생길 수 있어 선형으로 설명하기 쉽지 않다.
- 그러므로 S자 형태의 함수를 적용한다면 잘 설명할 수 있을 것 같다.
로짓 개념의 등장
- 오즈비: 승산비라 불리며 실패확률 대비 성공 확률을 의미한다.
- 예를 들어 도박이 성공할 확률이 80%라면 오즈비는 80% / 20% = 4이고, 1번 실패하면 4번은 딴다는 말이다.
- 수식: P / 1-P
하지만 오즈비는 바로 사용 불가
- P는 확률 값으로 0과 1사이의 값인데 P가 증가할수록 오즈비가 급격하게 증가하므로 너무 확률이 급격하게 증가하고 선형성을 따르지 않게 된다.
- 따라서 로그를 씌워 완화시킨다.
- 수식: log(P / 1-P)
오즈비와 확률의 관계 / 로짓과 확률의 관계
- 로짓의 그래프가 더 선형적인 그림을 나타내어 선형회귀의 기본식을 활용할 수 있게 됨
- 로지스틱 회귀라고 불리는 이유가 이것
로짓의 장점
- 어떤 값을 가져오더라도 반드시 특정 사건이 일어날 확률(Y)이 0과 1 사이를 가짐
로지스틱 함수는 가중치 값을 안다면 X값이 주어졌을 때 해당 사건이 일어날 수 있는 P의 확률을 계산할 수 있게 된다.
- 확률 0.5를 기준으로 그보다 높으면 사건이 일어남(P(Y) = 1)
- 그렇지 않으면 사건이 일어나지 않음(P(Y) = 0)으로 판단하여 분류 예측에 사용
분류 평가 지표
정확도와 F-1 score
- 회귀분석이 숫자를 예측하고 실제 값과 평가했던 것처럼, 분류에서는 맞춘 정답을 전체 개수로 나누면 될 것 같다
정확도의 한계
- 예시로 암 예측 모델을 생성
- 이 모델은 무조건 음성(정상)이라고만 판정
- 실제로 100명의 환자가 입실하였는데 100명 중 95명이 음성이었고 5명은 양성이었다.
- 이 때 모델의 정확도가 95%로 나온다.
- 정상도는 매우 높지만 실제로 양성은 하나도 맞추지 못함(사기)
혼동 행렬(confusion matrix): 사기를 잘 걸러내기 위해 F1_score 이용
- 예측을 암으로 했으면 Positive
- 예측을 암으로 하지 않았으면 Negative
- 맞췄으면 True
- 틀렸으면 False
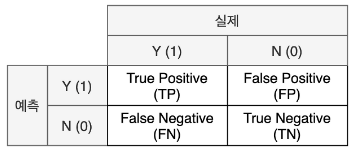
- 정밀도(Precision): 모델이 양성으로 예측한 결과 중 실제 양성의 비율
- TP / TP+FP
- 재현율(Recall): 실제 값이 양성인 데이터 중 모델이 양성으로 예측한 비율
- TP / TP+FN
- F1-score: 정밀도와 재현율의 조화 평균
- 2*(정밀도*재현율) / 정밀도+재현율
- 이걸 계산해보면 사기인지 아닌지 알 수 있음
- 정확도(Accuracy): 맞춘 비율
- TP + TN / TP + TN + FN + FP
정확도가 제 기능을 하지 못하는 경우
- 분류에서 특히 Y값이 unbalance할 때 발생
- 따라서 이를 위해 Y범주의 비율 맞춰주거나 평가 지표를 f1 score를 사용함으로써 보완
실습
함수
- sklearn.linear_model.LogisticRegression: 로지스틱회귀 모델 클래스
속성
- classes_: 클래스(Y)의 종류
- n_feature_in_: 들어간 독립변수(X) 개수
- feature_names_in_: 들어간 독립변수(X)의 이름
- coef_: 가중치
- intercept_: 바이어스
메소드
- fit: 데이터 학습
- predict: 데이터 예측
- predict_proba: 데이터가 Y=1일 확률을 예측
titanic 데이터
- 숫자: age, sibsp, parch, fare
- 범주: pclass, sex, deck, embark_town
- pclass 같은 경우 숫자이긴 하지만 좌석 등급이므로 범주형
결측치 확인

기술통계

x변수: fare, y변수: survived
from sklearn.linear_model import LogisticRegression
# 데이터의 분포
sns.histplot(titanic_df, x='fare')
# 산점도
sns.scatterplot(titanic_df, x='fare', y='survived')
# x, y
X_1 = titanic_df[['fare']]
y_true = titanic_df[['survived']]
model_lor = LogisticRegression()
model_lor.fit(X_1, y_true)
# 실행한 결과를 보고 싶을 떄마다 함수 호출해야 하므로 그냥 함수를 생성
def get_att(x):
# x 모델
print('클래스 종류', x.classes_)
print('독립변수 개수', x.n_features_in_)
print("들어간 독립변수(x) 이름", x.feature_names_in_)
print("가중치", x.coef_)
print("바이어스", x.intercept_)
평가 지표
from sklearn.metrics import accuracy_score, f1_score
# 함수 생성
def get_metrics(true, pred):
print("정확도", accuracy_score(true, pred))
print("f1-score", f1_score(true, pred))
# 각 사람이 생존했는지 못했는지 예측한 결과 array 형태로 보여줌
y_pred_1 = model_lor.predict(X_1)
y_pred_1[:10]
다중 로지스틱 회귀
- Y(survived): 사망률
- X(fare, embarked 승선항구): 수치형
- X(pclass 좌석등급, sex 성별): 범주형
- 널값이 있는 변수는 제외
# female, male을 0, 1으로 변경
def get_sex(x):
if x == 'female':
return 0
else:
return 1
titanic_df['sex_en'] = titanic_df['sex'].apply(get_sex)
model_lor_2 = LogisticRegression()
model_lor_2.fit(X_2, y_true)
# 예측
y_pred_2 = model_lor_2.predict(X_2)
y_pred_2[:10]
각 컬럼에 대해 죽었을 확률/생존할 확률

마무리
- 선형회귀의 아이디어에서 종속 변수(Y)만 가공한 것
- 장점: 직관적이며 이해하기 쉽다
- 단점: 복잡한 관계를 모델링하기 어려울 수 있음
선형회귀와 로지스틱회귀 공통점
- 모델 생성이 쉬움
- 가중치(혹은 회귀계수)를 통한 해석이 쉬움
- X변수에 범주형, 수치형 변수 둘 다 사용 가능
선형회귀와 로지스틱회귀 차이점
| 선형회귀(회귀) | 로지스틱회귀(분류) | |
| Y(종속변수) | 수치형 | 범주형 |
| 평가척도 | Mean Squared Error R Square(선형회귀만) |
Accuracy F1-score |
| sklearn 모델 클래스 | sklearn.linear_model.linearRegression | LogisticRegression |
| sklearn 평가 클래스 | sklearn.metrics.mean_squared_error sklearn.metrics.r2_score |
sklearn.metrics.accuracy_score sklearn.metrics.f1_score |